Take away message
- Observations: many errors are partially or completely related to contextual relationship and global information for different receptive field.
- Solution: exploit the capability of global context information by different-region-based context aggregation.
Model
observation about failures

- doesn’t match co-occurrent visual patterns
- confused by similar categories
- ignore small-size things / discontinuous prediction on large size things
Many errors are partially or completely related to contextual relationship and global information for different receptive fields. Thus a deep network with a suitable global-scene-level prior can much improve the performance of scene parsing.
pyramid scene parsing network (PSPNet)
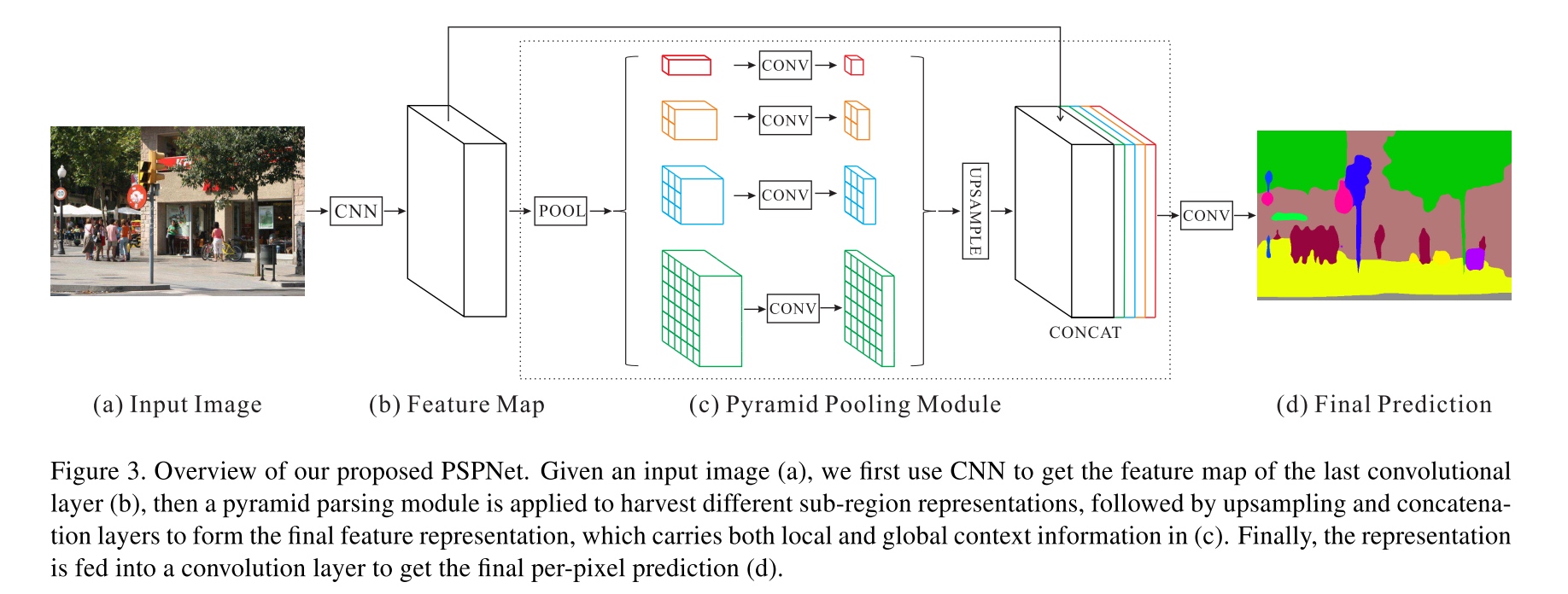
- Use a pretrained ResNet model with the dilated network strategy to extract the feature map. The final feature map size is 1/8 of the input image, as shown in Fig. 3(b).
- pyramid pooling module for global scene prior construction upon the final-layer-feature-map of the deep neural network.
- Use 1×1 convolution layer after each pyramid level to reduce the dimension of context representation to $\frac{1}{N}$ of the original one if the level size of pyramid is $N$. Then we directly upsample the low-dimension feature maps to get the same size feature as the original feature map via bilinear interpolation.
- Different levels of features are concatenated as the final pyramid pooling global feature. It is followed by a convolution layer to generate the final prediction map in (d).
Deep supervised loss
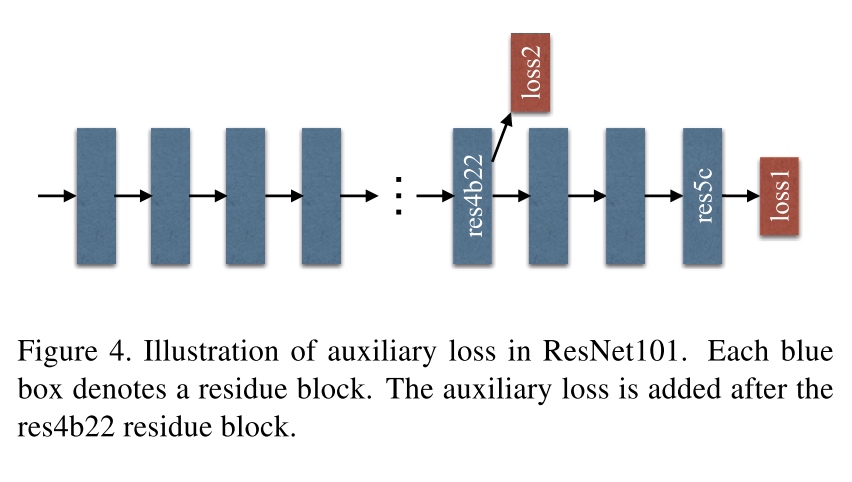
- Generating initial results by supervision with an additional loss, and learning the residue afterwards with the final loss. Thus, optimization of the deep network is decomposed into two, each is simpler to solve.
- The auxiliary loss helps optimize the learning process, while the master branch loss takes the most responsibility.
- In the testing phase, we abandon this auxiliary branch and only use the well optimized master branch for final prediction.
Result
Architecture for PSPNet
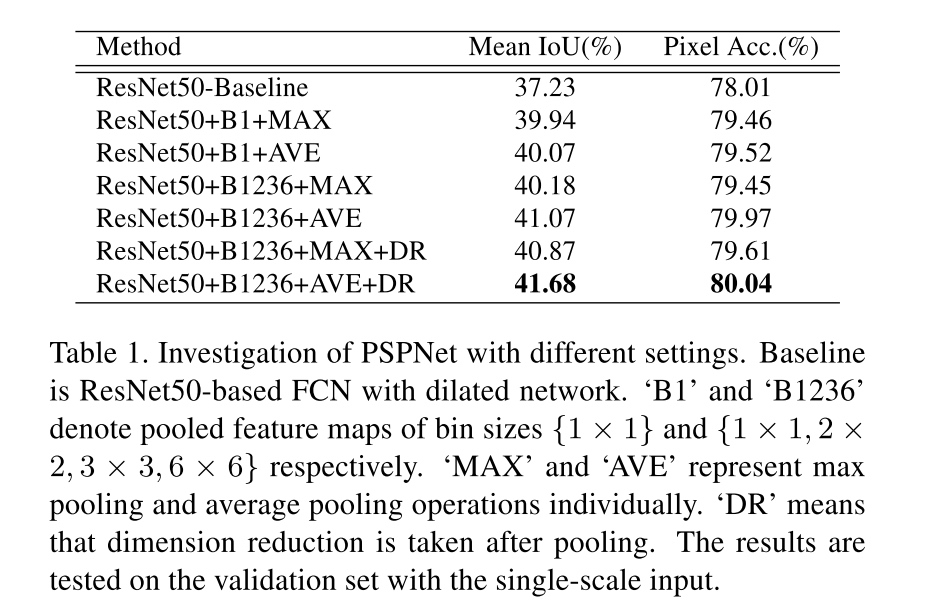
- average pooling works better than max pooling in all settings
- Pooling with pyramid parsing (B1236) outperforms that using global pooling (B1)
- With dimension reduction, the performance is further enhanced.
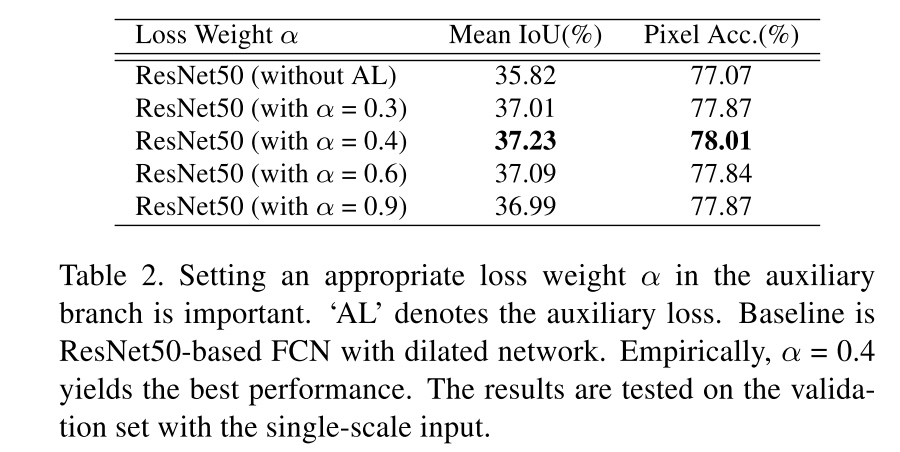
Auxiliary Loss
Pretrained model
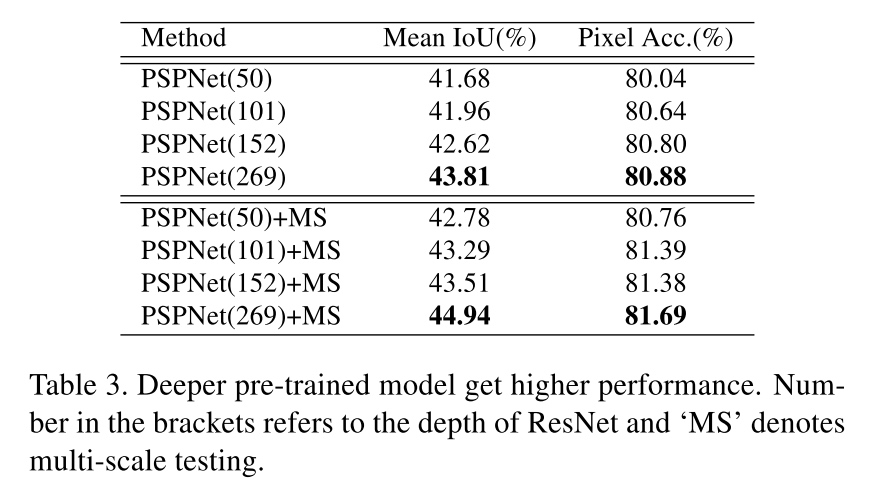
Detailed analysis
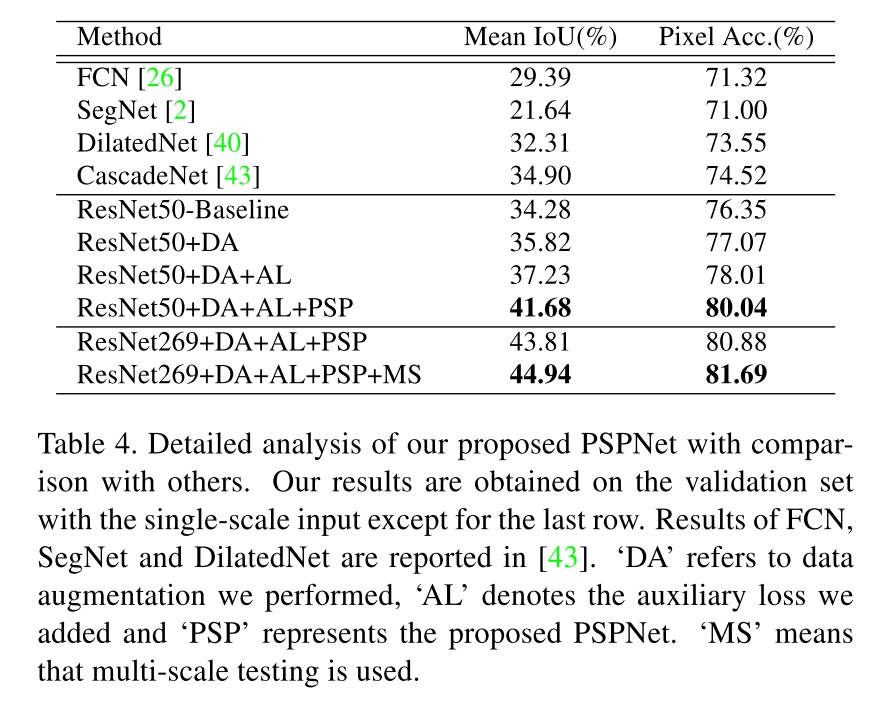
Others
需要注意各个方法的baseline是不是resnet
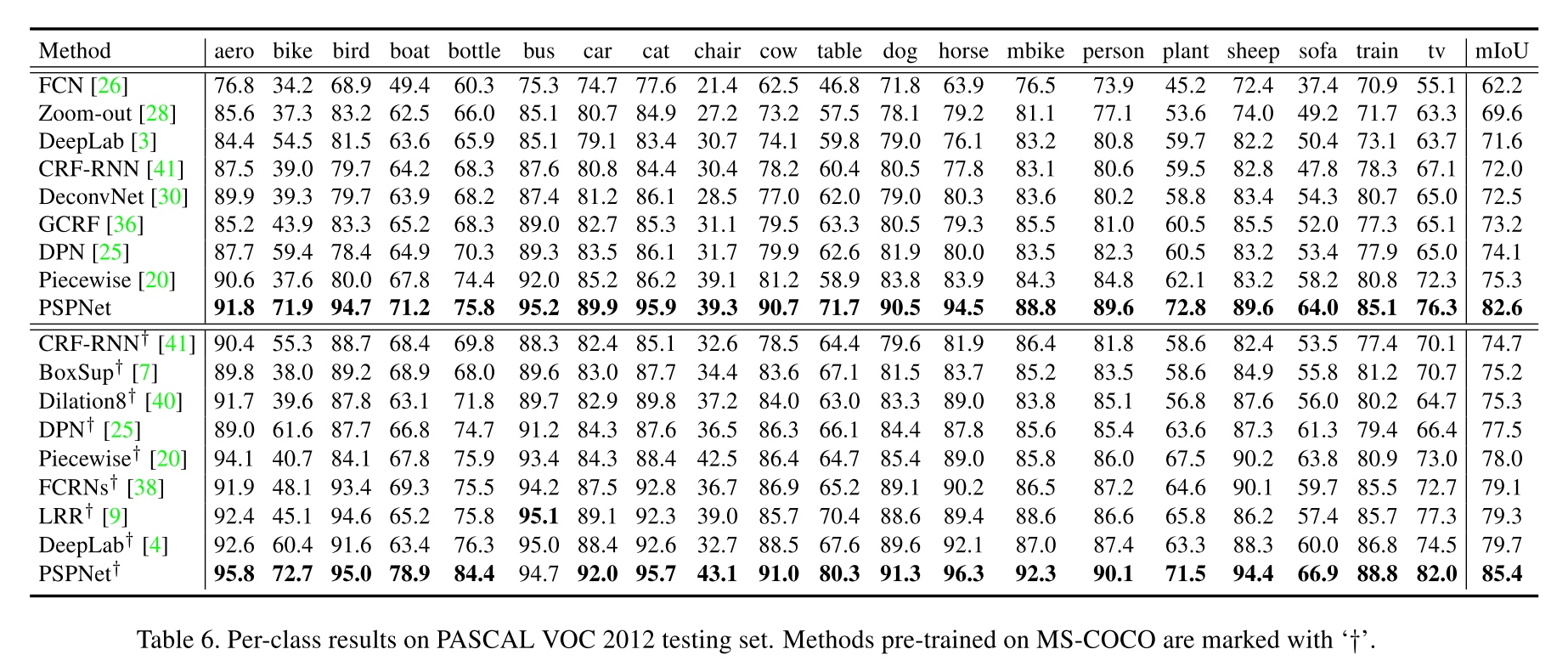
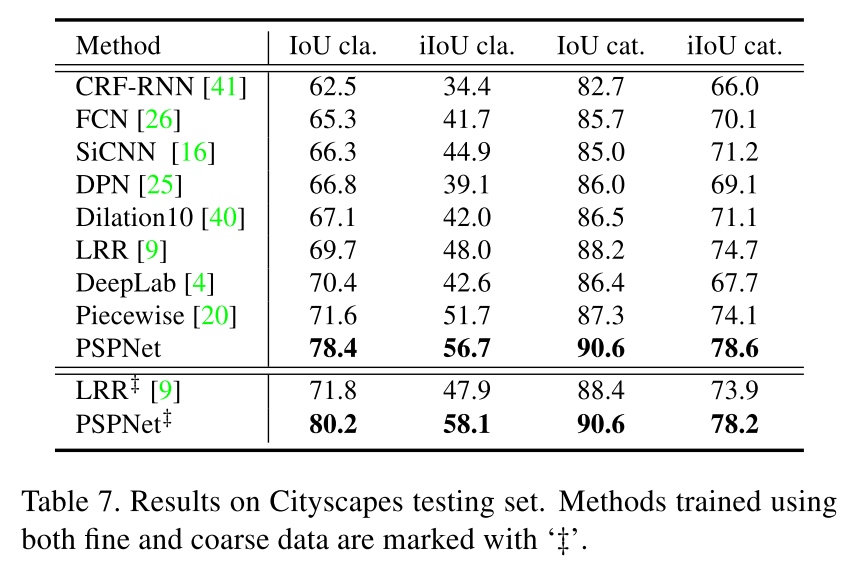
Further reference
- B. Zhou, A. Khosla, A.` Lapedriza, A. Oliva, and A. Torralba. Object detectors emerge in deep scene cnns. arXiv:1412.6856, 2014. 3. (The paper shows the empirical receptive field of CNN is much smaller than the theoretical one especially on high-level layers.)