Take away message
- We shouldn’t assume that the source and target domains share same intermediate feature space(s), i.e. using loss to obtain domain-invariant features.
- Use a conditional generator to transform source feature maps into target-like, and trained on the target-like feature maps and original labels (和pixel level domain adaptation类似,但pixel level DA将source images转化为target-like,而本文将source features转化为target-like).
- 文章中提到 without relying on the assumption that the source and target domains share a same prediction function in a domain-invariant feature space。 实际只完成了not in a domain-invariant feature space, 本质上还是same prediction function (source和target domain的encoder和decoder都相同)
Model
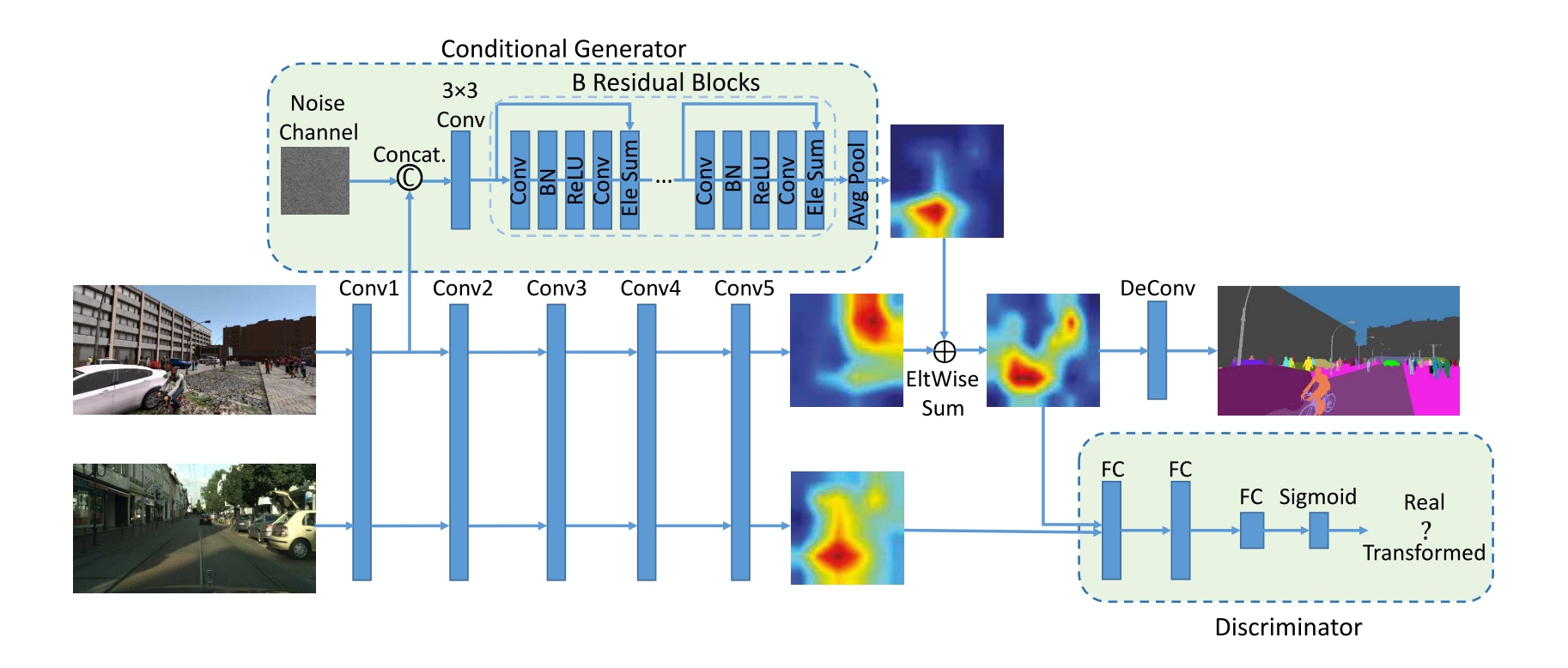
- a conditional generator to generate residual features, to transform features of synthetic images to real-image like features.
- a noise map $z$ is addd for randomness to create an unlimited number of training samples.
- expect that $x_f$ preserves the semantic of the source feature map $x_s$, meanwhile appears as if it were extracted from a target domain image, i.e., a real image.
- a discriminator to distinguish adapted source features and real target features.
- task-specific loss (decoder part)
- train T with both adapted and non-adapted source feature maps (Training T solely on adapted feature maps leads to similar performance, but requires many runs with different initializations and learning rates due to the instability of the GAN).
- overall minimax objective:
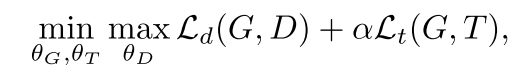
Result
-
overall performance: 涨幅非常大
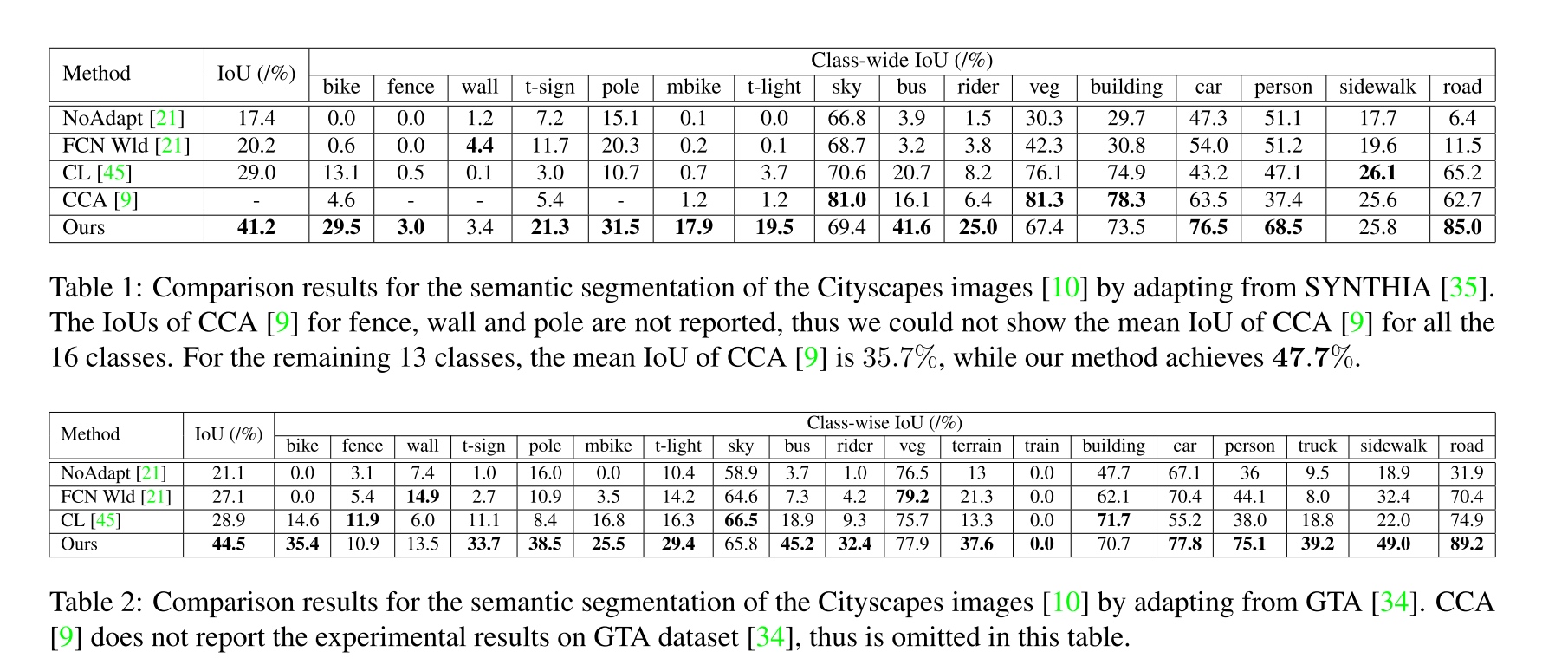
-
amount of synthetic data
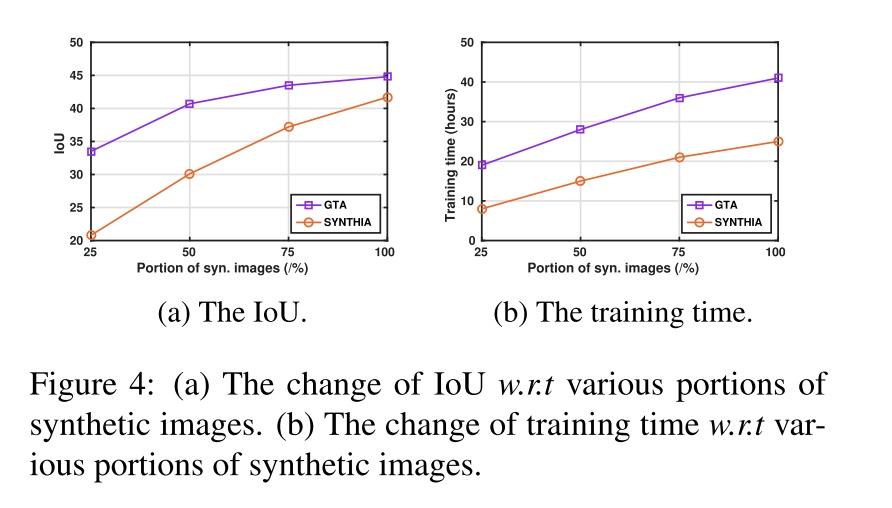
-
Ablation Studies
-
The effectiveness of conditional generator

- Different lower layers for learning generator
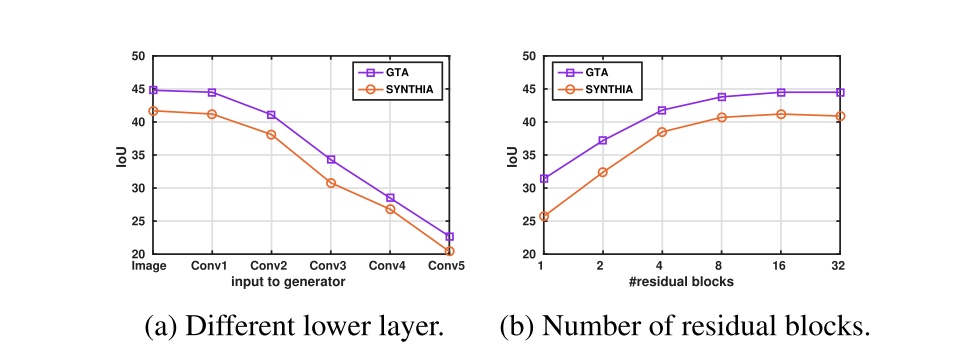
- On the number of residual blocks (上图)
- How much does the noise channel contribute?

-