Take away message
- In practice, we have to consider the cost of memory and computational time.
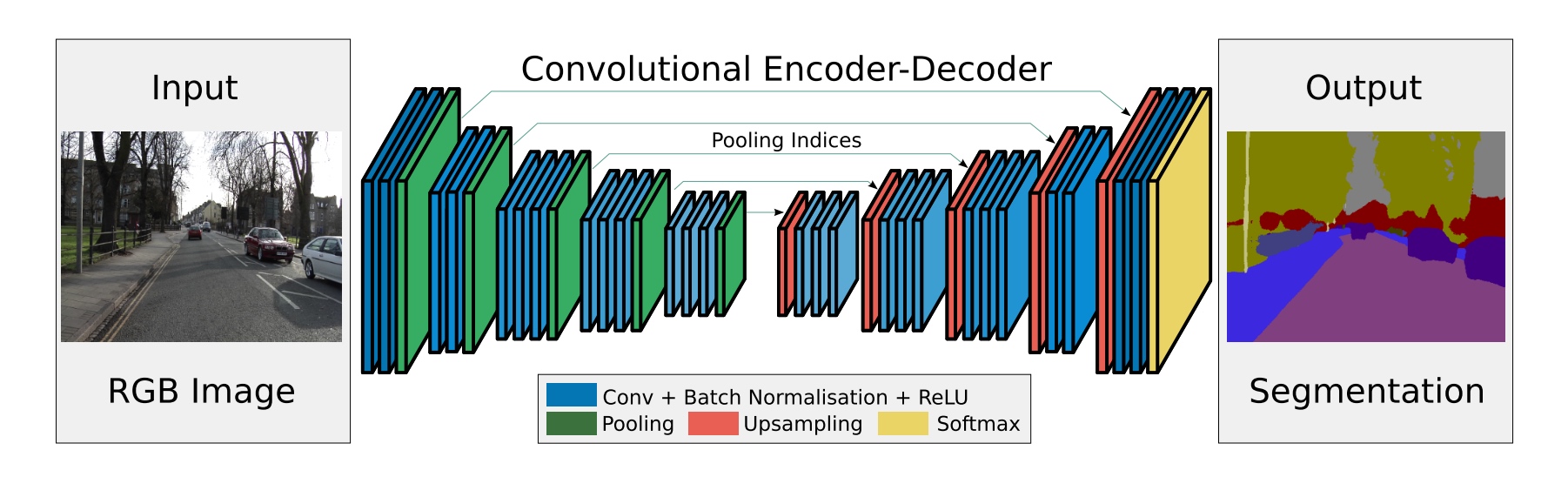
- Most recent deep architectures for segmentation have identical encoder networks, i.e VGG16, but differ in the form of the decoder network, training and inference.
Model
Encoder:
- The encoder network consists of 13 convolutional layers which correspond to the first 13 convolutional layers in the VGG16 network.
- Initialize the training process from weights trained for classification on large datasets.
- Benifit: Removing the fully connected layers of VGG16 makes the SegNet encoder network significantly smaller [reduces the number of parameters in the SegNet encoder network significantly (from 134M to 14.7M)] and easier to train.
Decoder:
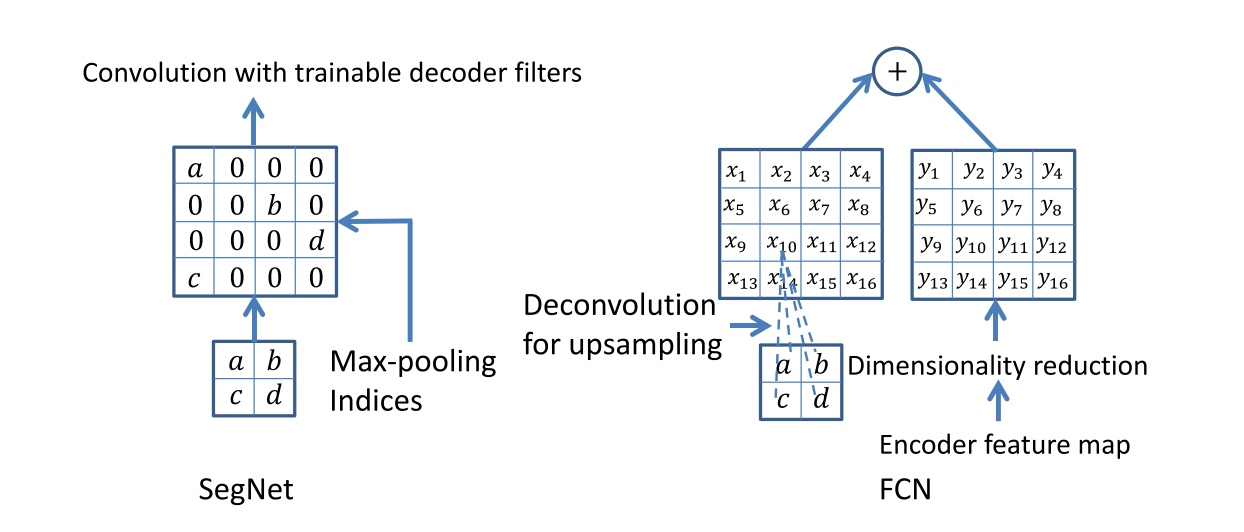
- The appropriate decoder in the decoder network upsamples its input feature map(s) using the memorized max-pooling indices from the corresponding encoder feature map(s). This step produces sparse feature map(s).
- These feature maps are then convolved with a trainable decoder filter bank to produce dense feature maps.
- Except for the last decoder (which corresponds to the first encoder), the other decoders in the network produce feature maps with the same number of size and channels as their encoder inputs.
Tricks
class balancing